Tutorial: ¿Cómo usar Screaming Frog SEO Spider?

Screaming Frog es una herramienta seo muy potente con la que podrás auditar todas las urls de tu sitio web. Gracias a ella, podrás ver fácilmente en que lugares tiene tu web problemas de seo on-page. Por ejemplo, podrás encontrar rápidamente páginas con error 404, comprobar el tamaño de todos tus encabezados h1 o descubrir bucles de redirecciones de los que no eras consciente.
En este tutorial de Screaming Frog voy a explicarte como configurar esta herramienta, así como a extraer y analizar toda la información de tu web para que puedas empezar a ponerla a punto a ojos de Google. Además, también te daré algunos consejos útiles que yo utilizo habitualmente. Así que… ¡Empecemos!
Índice del artículo
Descargar e instalar Screaming Frog SEO Spider
Antes de seguir, has de saber que Screaming Frog es una herramienta que ha de descargarse e instalarse en tu pc. Lo ideal es que te descargues la herramienta, la instales, y mientras vas leyendo este tutorial, tu mis@ vayas probando todas las opciones.
Puedes descargar la herramienta directamente desde su web oficial: Descargar Screaming Frog
Te darás cuenta rápidamente que existen dos versiones de este programa: una gratuita con limitaciones, y otra de pago. Las diferencias entre ellas son claras:
- Versión gratuita: El crawler (rastreador) de Screaming Frog tiene un alcance máximo de 500 urls. Además, no podrás utilizar las configuraciones avanzadas de las que te voy a hablar en este tutorial, ni las integraciones con Google Analytics, Google Pagespeed, etc…
- Versión pro o de pago: Sin limitaciones.
Como te mencioné antes, uno de los objetivos de este tutorial es explicarte como configurar Screaming Frog, para lo cual necesitarías la versión pro o de pago del programa. ¿Significa esto que si tienes la versión gratuita, este tutorial no te sirve de nada?. No. En la segunda parte del tutorial hablaré de los distintos datos que puedes extraer con Screaming Frog y como puedes interpretarlos, algo que SI puedes hacer con su versión gratuita (eso sí, con el límite de 500 urls).
Tus primeros pasos con la aplicación
Bien, empecemos a meternos ya en el lío. Después de que instales Screaming Frog, al abrirlo te encontrarás una interfaz repleta de botones, submenús y demás elementos que si sabes poco a nada de SEO te van a marear muchísimo. ¡No te preocupes!. Nos pasa a todos al principio y tan solo tardarás unos días en acostumbrarte.
- 1. El buscador. Su función es la de rastrear la web cuya url insertes en el cuadro de búsqueda. Se encuentra en la parte superior de la aplicación:
![]()
Antes de empezar a rastrear, es conveniente que sigas leyendo esta guía para ver las diferentes opciones de configuración de rastreo.
- 2. Los diferentes menús de configuración, reporte, exportación de datos, etc… Entraremos en detalle en ellos más adelante. Podrás encontrarlos también en la parte superior de la aplicación, justo encima del buscador.
![]()
- 3. El resto de la aplicación, donde podrás ver todos los datos extraídos de la web analizada.
Empezando a configurar Screaming Frog
Antes de empezar a rastrear una web, vamos a configurar el rastreador para que extraiga los datos que nosotros deseamos. No se trata de extraer todo lo que puedas, ya que la cantidad de información podría ser excesiva y al final solo conseguirás hacerte un lío.
La mayoría de las opciones de configuración se encuentran en el grupo 2 que describí anteriormente, evidentemente en el que tiene de nombre «configuración»:

Spider
Spider es una opción bastante útil para filtrar que elementos de la web quieres rastrear o no y como debe extraerse la información de la web. La primera pestaña que nos encontramos al abrir este submenú es «basic»:

Basic
Esta es una de las diferencias notables que hay entre la versión gratuita y pro de la aplicación, ya que en la gratuita nos listará todos los ficheros javascript, css, imágenes, etc… que se encuentren durante el rastreo, acaparando gran parte de ese límite de 500 urls a rastrear. En la opción pro, podremos filtrar todos esos elementos para que no sean rastreados, lo que nos devolverá un reporte mucho más legible.
Otro filtro que podemos aplicar es que el rastreador no siga los enlaces «nofollow» de tu web, lo que nos ayudará a deducir como podría comportarse GoogleBot a la hora de rastrear tu web y poder mejorar tu «crawl budget» o «presupuesto de rastreo».
También contamos con las opciones:
- «Crawl Outside of Start Folder»: Mas esta opción si alguna vez quieres empezar a rastrear desde algún directorio o página de tu web, y no desde la raíz del dominio.
- «Crawl all subdomains»: Podemos indicar a Screaming frog que pase por los subdominios enlazados en nuestra web, si los hubiera.
- «Crawl canonicals»: Si la desmarcamos, el rastreador guardará que url son canonicas o no cuando las encuentre, pero no entrará en ellas.
- «Crawl Next/Prev»: Igual que la anterior, pero en este caso no entraría en las páginas etiquetadas como next o prev.
- «Crawl hreflang»: Si tu web tiene varios idiomas y has puesto las etiquetas hreflang, quizás te interese extraer estos datos con la opción «extract» y seguir esos enlaces marcando esta opción.
- «Crawl AMP»: De nuevo, el funcionamiento es similar a las anteriores, pero esta opción es para seguir las etiquetas AMP. Evidentemente, si tu web no utiliza páginas AMP, no tendrías por que activar esta función.
- «Crawl Linked XML Sitemap»: Esta opción permite seguir enlaces de sitemaps XML si son encontrados, algo que no es habitual. Yo personalmente no activo nunca esta función.
Limits
Este submenú es bastante intuitivo. En el, podrás establecer que límites de rastreo quieres que Screaming Frog aplique durante el rastreo. Algunas de sus opciones pueden resultarte muy útiles para webs extremadamente grandes o complejas.
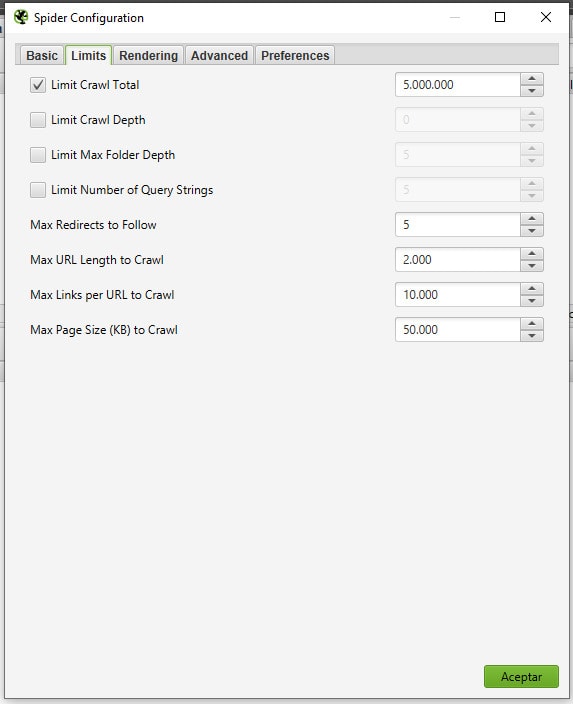
- «Limit Crawl Total»: Aquí indicamos la cantidad total de urls que queremos rastrear. Una vez que llegue al límite, Screaming Frog parará de rastrear. Generalmente lo que nos interesa es rastrear toda la web, así que si lo modificas será para ampliarlo (si es que lo llegas a modificar algún día).
- «Limit Crawl Depth»: Esta opción viene desactivada por defecto. Si la activas, puedes indicarle al rastreador que nivel de profundidad de la web quieres que tenga como límite. Por ejemplo, «1» solo dejaría que el rastreador siga los enlaces directos desde la home (a los que se puede llegar a solo 1 click). «2» establecería el límite a los enlaces a los que se puede llegar con 2 clicks desde la home. El resto de números ya puedes deducirlos.
- «Limit Crawl Folder Depth»: Similar a la anterior, pero para categorías de carpetas o directorios en vez de para páginas.
Estas 2 últimas opciones son particularmente útiles para saber si alguna página o categoría de tu web no es accesible en 3 clicks. Simplemente actívala con un 3 y rastrea tu web. Si la página o categoría que quieres comprobar no aparece en el listado de resultados de Screaming Frog, es que simplemente se encuentra a 4 clicks o más.
- «Limit Number of Query Strings»: Con esta opción puedes excluir las urls que tengan X parámetros o más. Si te estás preguntando que es un parámetro, es una url con sintaxis ?x=, como por ejemplo dominio.aaa/?pienso=seco. Estos parámetros son muy utilizados en programación PHP para transmitir datos a las páginas y son muy habituales, por ejemplo, en las tiendas online. El ejemplo anterior sería 1 parámetro. Un ejemplo con 2 parámetros sería dominio.aaa/?pienso=seco&sabor=salmon
- «Max Redirect to Follow»: Aquí nos metemos en algo interesante. Esta opción indica al rastreador el límite de redirecciones que se seguirá de una página a otra. Estos «bucles de redireccionamiento» destrozan el presupuesto de rastreo que Google da a nuestra web, por lo que deberíamos arreglarlos cuanto antes si no hay cosas más graves.
- «Limit URL Length to Crawl»: Este límite impide al rastreador seguir urls excesivamente largas. Por defecto esta en 2000 caracteres.
- «Max Links per URL to Crawl»: Gracias a esta opción, podremos especificar el número máximo de urls que queremos que sea rastreado en un sola página. Su configuración va a depender mucho de la web que vas a rastrear, ya que para unas 100 puede ser excesivo y para otras 500 puede ser poco. Por poner un ejemplo, me he encontrado webs con artículos a los que solo podías acceder desde la página de «mapa web». Si esta página tiene 1000 enlaces y tu tienes configurado seguir como máximo 500, jamas veras los otros 500. A la hora de hacer una auditoría SEO, quizás te convenga poner inicialmente un límite muy alto para sacar todo lo que haya, y después bajarlo.
- «Limit Page Size (KB) to Crawl»: Muy parecida a la anterior, pero en vez de poner como límite el número de enlaces, el límite es el tamaño en KB de la página.
Rendering
Esta pestaña contiene las opciones de renderizado de la página que queremos que se apliquen cada vez que nuestro «spider» o rastreador pase por una.

Por defecto tenemos 3 configuraciones posibles:
- «Text Only»: Cuando el rastreador pasa, solo analiza el texto plano en HTML. Esto deja atrás todos los datos que haya en la web a través de Javascript. Esta opción es útil si detectas problemas en la extracción de datos a través de las otras dos opciones.
- «Old AJAX Crawling Scheme»: Esta opción intenta hacer una emulación de como Google lee la página, pero a día de hoy se sabe que está obsoleta. Personalmente es la que habitualmente uso, y si me encuentro algún problema, cambio a «Text only».
- «Javascript»: Esta opción ejecuta el javascript que hay en nuestra página. Generalmente, yo solo la uso cuando quiero realizar las capturas de pantalla y ver como se muestra la página para el bot de Screaming frog. Evidentemente, esto ralentiza mucho la velocidad a la que el bot analiza toda la web.
Advanced
La siguiente pestaña tiene una serie de configuraciones extra que vas a modificar más a menudo que las anteriormente vistas.
Empecemos desde el principio:
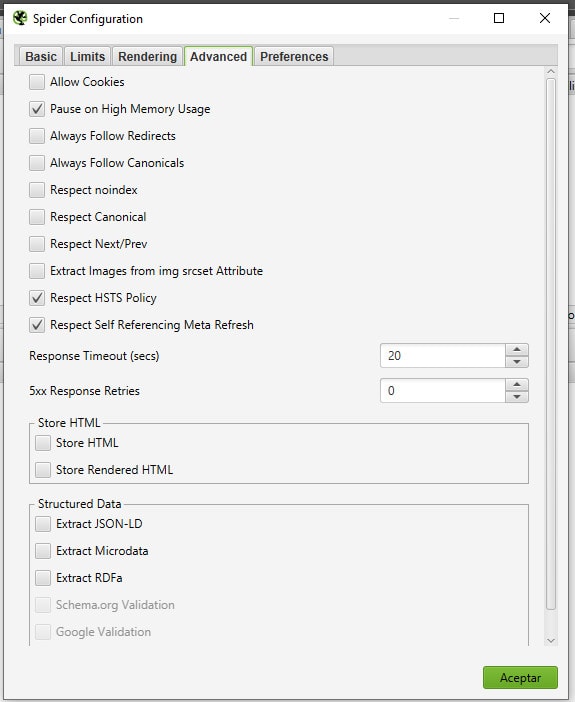
- «Advanced cookies»: Una opción interesante. De primeras te estarás preguntando que tienen que ver las cookies con Screaming frog. La respuesta es a su vez otra pregunta. ¿Qué pasa si el spider entra en una de esas web que no te dejan hacer nada si no aceptas las cookies?. Si la web que vas a rastrear es uno de estos caso, ¡tan solo activa esta opción!
- «Pause on High Memory Usage»: Esta opción pausa el crawleo si Screaming frog llega a saturar la memoria de tu pc.
- «Always Follow Redirects»: Algo similar a la opción «Max Redirect to Follow» que podemos encontrar en la pestaña «basic», con la diferencia de que aquí no establece ningún tipo de límite. La funcionalidad es la misma, descubrir los bucles de re-direccionamiento para posteriormente arreglarlos.
- «Always Follow Canonicals»: Permite al spider seguir los canonicals hasta su url final, independientemente de lo que hayamos configurado en la opción «Limit Crawl Depth» de la pestaña «Limits».
- «Respect Noindex»: Si la activas, en el informe no se mostrarán las urls que tengas etiquetadas como «noindex».
- «Respect Canonical»: Similar a la anterior, pero en este caso lo que no se muestra en el informe son esas páginas cuyas etiquetas canonical no apuntan a sí mismas.
- «Respect Noindex»: En este caso, si tu web tiene instaladas las etiquetas next y prev para las paginaciones, solo sacará en el informe aquellas páginas que tienen la etiqueta next pero no la prev. Esta coincidencia solo se da en las páginas «1» de las páginaciones típicas que podemos encontrar en blogs, periódicos online, etc.
- «Extract Images from img srcset Attribute»: Esta opción permite al rastreador extraer las imágenes que carguen a través del atributo srcset.
- «Respect HSTS Policy»: Si tu web tiene instalado el protocolo HTTPS, lo más normal es que todas tus urls carguen con el. Lejos de eso, un error bastante común a nivel SEO es tener páginas que cargan también como HTTP. Con esta directiva activada, si el rastreador encuentra una url http en un sitio https, te la mostrará con el código de estado 307 para que puedas localizarla y solucionar el problema.
- «Respect Self Referencing Meta Refresh»: Esta opción es algo más compleja de explicar, por lo que lo haré a través de un ejemplo práctico y extremadamente habitual. Imaginemos que tenemos una url que recibe 2 redirecciones, por ejemplo https://dominio.aaa/perros recibe las redirecciones de http://dominio.aaa/perros y https://www.dominio.aaa/perros. En este caso, si el spider encontrara en tu sitio cualquiera de las 2 urls no originales, las que hacen redirección a https://dominio.aaa/perros, marcaría estas urls como «No indexables». Evidentemente te interesa dejar esta opción activada.
- «Response Timeout»: Define el tiempo límite en segundos que el spider esperará a que cargue una url. Si no carga en ese tiempo, dará un error de conexión.
- «5XX Response Retries»: Este campo establece el número de veces que el rastreador intentará acceder a una url que dé error 5xx. Si por ejemplo, lo ponemos en 2, intentará acceder solo 2 veces. Si no consigue entrar después de 2 veces, el spider continuará su camino sin acceder a esa página en concreto.
Hasta aquí la parte que más solemos cambiar de configuración según las pruebas que queramos hacer. Las siguientes 8 opciones no se suelen tocar a menudo, pero si activar, especialmente por la comodidad de no tener que repetir la misma prueba con otra aplicación.
- «Store HTML y Store Rendered HTML»: Con ambas activadas, Screaming frog guardará el html de cada página analizada (para la primera opción) y un renderizado de ella (para la segunda), de forma que tu puedas consultarlo durante el análisis de la web. Ambos informes pueden venirte muy bien para identificar por que cierto dato no te es mostrado durante el análisis, ya que es posible que se deba a una mala ejecución de Javascript.
Es importante recordar que el renderizado de la página solo será visible si, previamente, hemos marcado la opción «Javascript» en la pestaña «Rendering»
- «Extract JSON-LD, Extract Microdata y Extract RDFa»: Permiten extraer y guardar estos conjuntos de datos, aunque no se se hayan programado o etiquetado correctamente (en el siguiente punto hablo de la validación de estos datos). Esta opción es útil porque si, por ejemplo, Screaming frog no te detecta las «breadcrumps» instaladas mediante JSON-LD, es un indicio de que debes comprobarlas. Es probable que se encuentren mal instaladas y Google tampoco pueda «entenderlas».
- «Schema.org Validation, Google Validation y Case Sensitive»: Después de extraer los datos con las opciones anteriores, si activas estas funciones, Screaming frog los analiza y te avisa de si están bien instalados, hay errores, o simplemente advertencias. En la web oficial de Screaming Frog podrás encontrar un montón de ejemplos de diferentes validaciones y de como interpretar estos datos: structured data testing validation.
Preferences
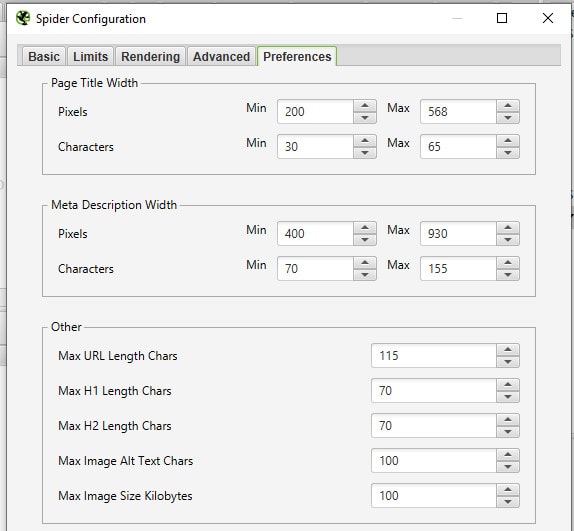
Conforme vayas utilizando Screaming Frog, te darás cuenta que tienes a tu disposición muchos filtros que te indican cuando ciertos «valores» superan el tamaño recomendado. Entre ellos, se encuentran el meta-title, meta-description, h1, h2, las urls…
Estos límites vienen configurados por defecto con unos valores que han definido los desarrolladores de Screaming Frog, pero puedes modificarlos a tu gusto si te es necesario.
Robost.txt
Una vez que hemos acabado de configurar el Spider, pasamos a la segunda opción dentro del menú de Screaming Frog: Robost.txt.
En este apartado tenemos 2 submenús: Settings y Custom.
Settings

- «Respect robost.txt»: Con esta configuración, el rastreador no entrará en ninguna url que esté bloqueada por el robost.txt, aunque tengas enlaces a ellas en cualquier sitio de tu web.
- «Ignore robost.txt»: Al contrario que la opción anterior, el rastreador entrará en todas las urls que encuentre en tu web a pesar de que estén bloqueadas en el robost.txt. Puede ser útil, por ejemplo, para detectar urls a las que los usuarios o el bot de Google están accediendo porque se te haya olvidado retirar un enlace.
- «Ignore robost.txt but report status»: Muy similar a la anterior, el rastreador de Screaming frog entrará en todas las urls que encuentre sin hacer caso a lo que tengas en el robost.txt. ¿Donde se encuentra la diferencia? Con esta opción marcada en vez de la otra, en el reporte final de los datos te mostrará todas esas urls, pero te indicará que se encuentran bloqueadas por robost.txt.
Custom
Respecto a la pestaña «Custom», no entraré en detalles porque va más aya de la configuración básica, que es de lo que trata este tutorial. Sin embargo, si te daré una pista por si un día necesitas usarlo, tener presente que esta herramienta está ahí.
Esta pestaña permite, básicamente, combinar las directivas de tu robost.txt con las que tu añadas aquí. Es útil, por ejemplo, para hacer pruebas de como se comporta un rastreador antes de implementar una o varias directivas en el robost.txt de tu web.
User-Agent
Llegamos al último punto que has de conocer de configuración básica.
Este submenú se encuentra algo más abajo que el resto. Fíjate en la siguiente imágen si no lo encuentras:
Una vez que abras el submenú, encontrarás lo siguiente:

En este desplegable podrás seleccionar el «user-agent» o agente de usuario con el que quieres que el spider bot acceda a tu fichero robost.txt y, por tanto, siga las directivas de rastreo que tiene.
¿Por que es importante conocer esta configuración? Porque Screaming Frog tiene su propio user-agent, lo cual significa que puedes añadir en tu robost.txt directivas específicas para el. Por ejemplo, para nunca entrar en una parte específica de tu web. Esto puede ser realmente útil si tienes una web enorme y cada rastreo tarda en realizarse mucho tiempo.
En caso de que no haya directivas específicas para Screaming frog en tu robost.txt, según la documentación oficial, el spider seguirá las directivas en activo para GoogleBot y, en caso de que estas tampoco existan, seguirá las directivas para todos (*) los bots.
Guardando la nueva configuración
Sin duda lo más importante. Antes de cerrar Screaming frog para su próximo uso, asegúrate de guardar todos los cambios que hayas hecho en su configuración.
Puedes hacerlo en el siguiente menú: File -> Configuration -> Save Current Configuration as Default
Analizando los datos extraídos con Screaming Frog
Ya ha llegado el momento que seguro que estabas esperando. Te has tirado media tarde configurando la aplicación, pero aún no has alcanzado a comprender que vas a conseguir con todo esto, ¿verdad?. ¡No te preocupes!.
Lo siguiente que te voy a explicar es como le puedes sacar partido a todo lo que te he explicado hasta ahora. Antes de seguir, de nuevo te recomiendo que vayas haciendo lo que te explico conforme lees. Por esta razón, para continuar, lo primero que necesitas hacer elegir la web que quieres analizar.
Una vez que te hayas decido, pon la url de la web en el buscador que encontrarás en la parte superior de la página y dale a «start». El proceso de rastreo puede llegar a tardar bastante, dependiendo de las configuraciones que hayas aplicado y el tamaño total de la web.
Cuando hayas acabado, veras un montón de datos. No te apresures. Vamos a comenzar por lo básico, enseñándote cuales son los diferentes «filtros» que te ayudarán a ordenar los datos.
Los filtros o «pestañas» de Screaming frog te ayudarán a centrarte en áreas específicas de los datos, de manera que no te perderas entre el mar de información que te sale en pantalla.
Vas a contar con 3 grupos:
- El primer grupo es un conjunto de pestañas que encontraras en la parte superior de la aplicación, justo debajo del buscador. Este grupo te permitirá acceder a todos los datos de su correspondiente pestaña. Por ejemplo, todos los datos referentes a tus h1, a tus paginaciones, a tus urls…
![]()
- El segundo es todo el bloque de la derecha. La información que presenta está mejor organizada que el de arriba, ya que, digamos, tiene varios filtros para de cada «pestaña». Por ejemplo, puedes acceder con un click solo a los h1 demasiado largos, a tus paginaciones marcadas como no indexables o a las urls que tengan al menos una letra en mayúsculas.

Para explicarte el tercer grupo de información, primero es necesario que realices una pequeñas acción.
Al terminar el rastreo, te habrás dado cuenta que la zona central se ha llenado de información:

Si haces click en cualquiera de esas líneas, verás que justo debajo aparece aún mas información, dividida en diferentes pestañas. Este es el tercer grupo.
- El tercer grupo cuenta con información específica de cada url de la lista. Podrás ver que urls tienen un enlace a la página que has clickado, si tiene datos estructurados y están bien implementados… E incluso, si activaste el «spider» en modo «javascript», obtendrás un renderizado de la página.

Ejemplos prácticos básicos
Para practicar un poco vamos a realizar 3 ejemplos de recolección de información, uno para cara grupo de «pestañas» que acabamos de ver.
Ejemplo 1
En el primer ejemplo, vamos a analizar los datos que nos da la pestaña «response codes» del menú superior.

En esta pestaña podrás encontrar la siguiente información:
- Address: Es la dirección url que se ha analizado.
- Content: Da información sobre la codificación de la página o elemento en cuestión. Si la fila es una imágen, te da su formato (jpg, png, gif…). Si es una página de tu web, te indicará si está codificada como texto plano/html y el charset. En este caso sería interesante comprobar que todas las páginas tienen estándares similares en la codificación.
- Status code: Es el código de respuesta que nuestro servidor le da al usuario cuando solicita la página. Aquí tenemos que comprobar que todo se encuentra en código 200, que significa «OK». Si encuentras códigos 404 (página no encontrada), deberías hacer una redirección a una página con código 200 y que hable del mismo tema. Otros códigos que te puedes encontrar y que deberías ir arreglando poco a poco son 5xx (error del servidor), 301 (redirección permanente) ó 302 (redirección temporal). Aquí te dejo una lista de los diferentes códigos de respuesta que existen.
Los códigos de redirección como 301 o 302 no suelen suponer un problema en pequeñas cantidades. El problema lo tendrás si tienes bucles de más de 5-6 redirecciones hasta llegar a la final, ya que esto estropea mucho el crawl budget o presupuesto de rastreo de tu web.
- Status: Por decirlo de alguna manera, es una definición de «Status code». Para las redirecciones 301 te mostrará «Moved», para los «200», «OK»… Lo más relevante es que si la url en cuestión está bloqueada por el robost.txt, aquí te saldrá un mensaje personalizado como los anteriores, informándote de ello.
- Indexability: Te indica si la url está como indexable o no. Ojo con esto, si la url debería estar indexada y te la marca como no indexable, has de arreglarlo.
- Indexability Status: Te indica la razón por la que las url se han marcado anteriormente como «no indexables», si es que las hubiera. Por ejemplo, en una redirección te dirá «Moved» (obviamente, si la página se ha movido, no se ha de indexar su anterior url), y si la razón vuelve a ser el roboxt.txt, te lo volverá a indicar.
- Inlinks: Cantidad de enlaces entrantes que tiene la url.
- Response Time: Tiempo que ha tardado la página en responder, en mili-segundos. 1000 mili-segundos equivalen a 1 segundo.
- Redirect URL: En caso de la url haya sido redirigida, te indicará a cual.
- Redirect Type: Te indica el tipo de redirección que se ha hecho. Lo normal es que sean HTTP.
Como truco extra, si pinchas con el ratón en estos nombres, podrás filtrar los datos de mayor a menor o al revés. Utiliza esta función para, por ejemplo, agrupar todos los códigos de respuesta 404 en el mismo sitio y no tener que buscarlos 1 a 1.
Ejemplo 2
Ahora vamos a trabajar sobre el grupo de la derecha. En este caso, vamos a buscar toda la información relevante sobre los h1 y h2 de tu web.
Desliza la rueda del ratón hacia abajo hasta encontrar las etiquetas h1 y h2. Si tienes problemas, puedes utilizar también la pequeña barra de scroll que se encuentra a la derecha.
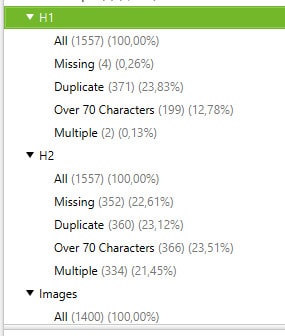
Si te fijas, la información presentada para ambos es la misma, así que te explico 2×1:
- All: Te muestra toda la información. Si te fijas, todos los «grupos» del menú derecho tienen un filtro «All». Pinchar en estos filtros es lo mismo que si pincharas en el correspondiente menú del primero grupo, el que explique anteriormente.
- Missing: Aquí ya tenemos que prestar atención. El número que aparece a la derecha (4 en h1 y 352 en h2) es el número de páginas que no tienen h1 y h2. En el h2 no es tan grave, pero si mejorable. Sin embargo, que falten h1 si es un error seo grave.
- Duplicate: En este caso te indica cuantos h1 y h2 hay duplicados con otras páginas, lo cual también es un error.
- Over 70 Characters: Este filtro se basa en la configuración de la pestaña «Advanced» en «Spider» que hicimos anteriormente, así que no te preocupes si a ti te sale otro número. Puedes cambiar esta configuración cuando quieras y volver a rastrear. En este caso te está indicando, evidentemente, que h1 y h2 son más largos de lo que deberían según tus condiciones.
- Multiple: Parecido a duplicate, pero no igual. Indica que h1 y h2 hay duplicados, ¡pero en la misma página!
Más truquitos, aunque este seguro que ya lo has averiguado 😝. Si clickas con el ratón en cualquiera de esos «filtros», la ventana central se actualizará y te mostrará directamente la urls afectadas. Por ejemplo, en duplicate de h1 te mostraría las 371 urls que comparten el mismo h1.
Ejemplo 3
Para realizar este ejemplo vamos a utilizar la información de las urls del ejemplo 1. Vuelve al menú superior y clicka en «Response codes».
Ahora, si clickas en una de ellas, verás que en la parte inferior se actualizan los datos. Vamos a buscar una función muy útil y que seguro que utilizarás en el futuro, ver los enlaces entrantes (Inlinks). La encontrarás abajo del todo, junto a otras pestañas como «Outlinks» (enlaces salientes) o «SERP Snippet» (para pre-visualizar como Google mostrará tu página en una búsqueda).

Para este ejemplo he seleccionado una imagen, por una razón muy específica.
Plantéate el siguiente reto: Mediante el informe que hemos visto en el ejemplo 1, descubres que en tu web tienes imágenes con código de estado 404. Decides arreglarlo con una redirección, ¡pero no no consigues encontrar de ninguna manera donde se encuentra esa imagen!
Esto es tremendamente habitual, especialmente si trabajas para clientes y estos han estado subiendo a su web imágenes cuyos nombres son cadenas de nombres y números aleatorios.
Esto que te acabo de enseñar es la forma más rapida y efectiva de encontrar que url (la que ves a la izquierda en la imagen) lleva a la imagen.
Otro truco adicional: Si en vez de clickar un solo enlace en la ventana central, seleccionas un grupo de varias urls, toda la ventana inferior se actualizará y te mostrará los datos en conjunto de esas urls.
Ejemplo práctico con etiquetas hreflangs
Para que entiendas este ejemplo, te recomiendo que al mismo tiempo que lees, rastrees una página cualquiera y compruebes tu mism@ los resultados de tu análisis. Puedes utilizar, por ejemplo, la web de una multinacional.
Para empezar, después del análisis busca la opción hreflangs en el menú derecho:
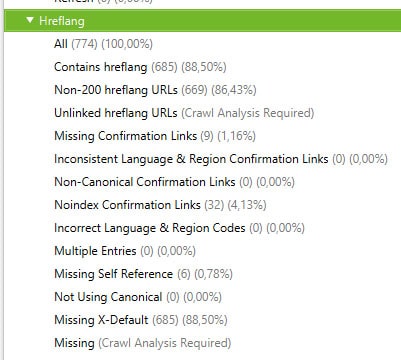
Como verás en esta imagen, algunos de los filtros aparecen como «Crawl Analysis Required». A veces, para completar ciertos datos, Screaming Frog necesita que hagas unos «análisis especiales». Para completar este análisis, busca en el menú superior la opción «Crawl Analysis» -> «Configure», para determinar el tipo de análisis que quieres (en este caso hreflangs).

Posteriormente, utiliza el menú «Crawl Analysis» -> «Start» para comenzarlo.

Ahora que ya tienes todos los datos, te daré una breve explicación de cada punto que puedes revisar:
- Contains hreflang: Te da el total de urls que tienen un idioma aparte del propio de la web. Si no está al 100% puede ser que haya productos o servicios que se vendan solo en España y no tengan equivalente en otros idiomas. A nivel SEO, deberás comprobar si esa es la razón o si simplemente no se pusieron las etiquetas hreflang. En caso de que no se hayan añadido y, si al mirar los otros idiomas ves que el contenido es muy similar, lo más aconsejable es implantar las etiquetas hreflang.
- Non-200 hreflangs urls: Esta si puede indicar un error importante. Aquí se muestran las urls que tienen una etiqueta hreflang con otro idioma indicado, pero la url de ese otro idioma presenta algún código de estado que no es el «200», que significa página encontrada. En el ejemplo podemos ver que hay una diferencia de aproximádamente un 2% entre esta directiva y el total de «contains hreflang». Podrían ser códigos 404, simples redirecciones 301, errores 5xx… Deberás averiguar cuales son esos códigos y si los productos ya no existen, actualizar las etiquetas o hacer las redirecciones pertinentes.
- Unlinked hreflangs ulrs: Son páginas de producto que no tienen ningún enlace natural a su otra versión en otro idioma. Las etiquetas hreflang no transmiten autoridad, por lo que se recomienda poner un enlace a tus productos en otros idiomas para transmitírsela por esta vía.
- Missing confirmation links: Este punto se refiere a que tienes una etiqueta hreflang, por ejemplo de un producto en español al inglés, pero falta la misma etiqueta en el producto inglés que indique cual es su versión en español. Deberás revisar cuales son las que faltan y ponerlas.
- Inconsistent Language & Region Confirmation Links: Esta directiva indica si hay diferencias entre el idioma indicado en las hreflang y la región también indicada en la etiqueta. Has de saber que puedes indicar para una misma región, por ejemplo bélgica, dos idiomas: el holandés y el francés. Lo que no tendría sentido, y por tanto mostraría errores este punto, es que tuvieras el holandés en España.
- Non Canonical Confirmation Links: Indica errores si el enlace de las hreflangs al otro idioma resulta ser una página NO canónica porque contiene una etiqueta rel=’canonical’ que apunta a otra página. En este caso, deberías cambiar la url proporcionada en la etiqueta hreflang para que apunte directamente a la url canónica.
- Noindex Confirmation Links: Parecida a la anterior, esta directiva da errores si el enlace de la etiqueta hreflang al otro idioma apunta a una página marcada como NO indexable.
- Incorrect Language & Region Codes: Presenta errores cuando el código de idioma puesto en la etiqueta hreflang NO es correcto. El código de idioma debe ponerse en formato ISO 639-1, puedes ver ejemplos en wikipedia.
- Multiple Entries: Aquí podrás ver si hay páginas que tienen 2 o más etiquetas hreflang instaladas, pero que indican distintos idiomas y la misma url objetivo. Cada url indicada en una etiqueta hreflang debe hacer referencia a un solo idioma.
- Missing Self Reference: Indica las etiquetas hreflang a las que les falta el atributo rel=’alternate’, que es de uso obligatorio.
- Not Using Canonical: Aquí podrás comprobar las urls de etiquetas hreflang que no son canónicas. A diferencia del punto «Non Canonical Confirmation Links», este se refiere a que no se indica una url canónica en concreto, sea a otra página o hacia sí misma. Si es hacia otra página, te dará error en «Non Canonical Confirmation Links», pero si el error se te muestra aquí, añade una etiqueta rel=’canonical’ en esa página y que apunte a sí misma.
- Missing X-Default: Indica si la url de la etiqueta hreflang no tiene el atributo «X-Default», pero este atributo es opcional. Que no esté no es necesariamente un problema.
- Missing: Aquí nos mostrará las urls de la web que no tienen declarada ninguna etiqueta hreflang. Como dije antes, esto no es necesariamente un problema porque puede haber productos o servicios que no existan en otros idiomas. Lo que tendrás que comprobar es si es así o falta declarar las hreflang en estas páginas.
Exportar los datos de Screaming Frog a Excel
Llegamos a la última parte de este tutorial. Como habrás podido comprobar ya, Screaming Frog es una herramienta super potente para realizar auditorías SEO. Pero no todo acaba aquí.
Una de las funciones que más usamos los SEO cuando trabajamos con Screaming frog es la exportación de datos en excel. Tienes dos formas de exportar los datos:
- La primera es utilizando los diferentes iconos con el nombre «Export» que ya habrás encontrado a través de la interfaz de la aplicación. Puedes encontrar uno, por ejemplo, justo debajo del menú superior:

- La segunda opción se llama «Bulk Export» y podrás encontrarla justo encima, en el menú superior de configuraciones:

¿Existen diferencias entre ambos tipos de reportes? Si. El de la primera imagen depende de en que pestaña o filtro te encuentres dentro del propio Screaming Frog, y te exportará los datos que se vean en la ventana central.
Por el contrario, «Bulk Export» te construye reportes ya predefinidos. La mayoría de nombres son muy intuitivos y, adicionalmente, las exportaciones de «Bulk Export» suelen mostrar conjuntos de datos más completas que los otros.
¿Qué te ha parecido este tutorial?
¡Déjame un comentario con tu feedback o tus dudas y te responderé!
Elena
Posteado el 16:28h, 20 abrilMuy bueno y muy completo Abraham, gracias!
Abraham Antona
Posteado el 19:18h, 28 mayoGracias a ti Elena, ¡espero haberte ayudado!
claudia
Posteado el 12:38h, 08 octubreMuy buenas Abraham. Estoy intentando configurar Screaming para que me detecte las urls huérfanas. Al principio me pedía configuración, así que le he dicho exactamente cuál era la ubicación del sitemap.xml. Sin embargo, me dice 'crawl analysis required' y no sé cuál es el problema, porque tengo activada la pestaña. ¿Alguna idea? Un saludo
Abraham Antona
Posteado el 19:09h, 23 julioBuenas tardes Claudia.
Una vez que finaliza el análisis inicial (el que se ejecuta dándole al botón de start), tienes que buscar en el menú superior la opción "crawl analysis" y darle a "start". Con ello se ejecuta un segundo análisis que es el que te solicita 🙂
Espero haberte ayudado.
Un saludo!